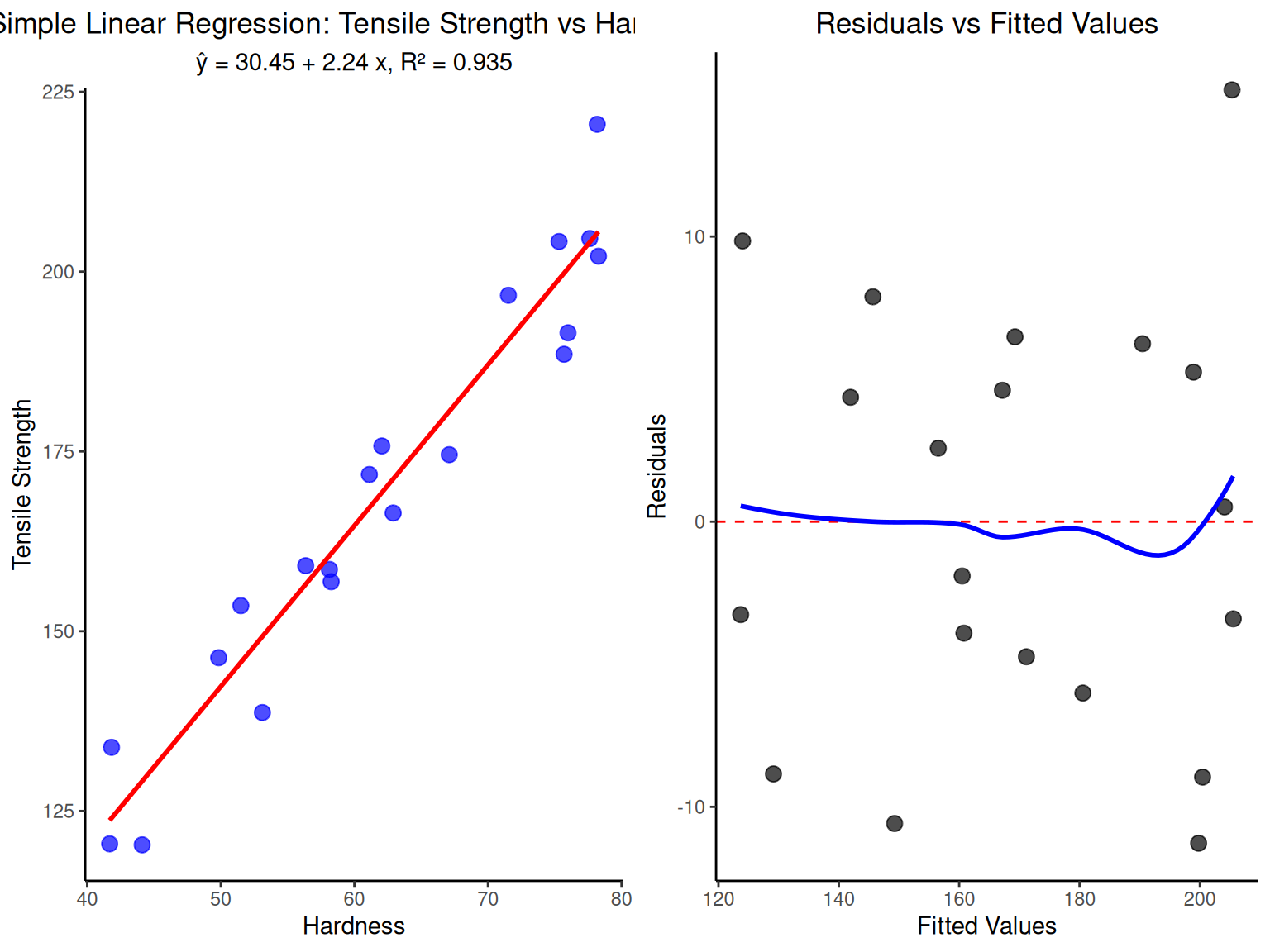
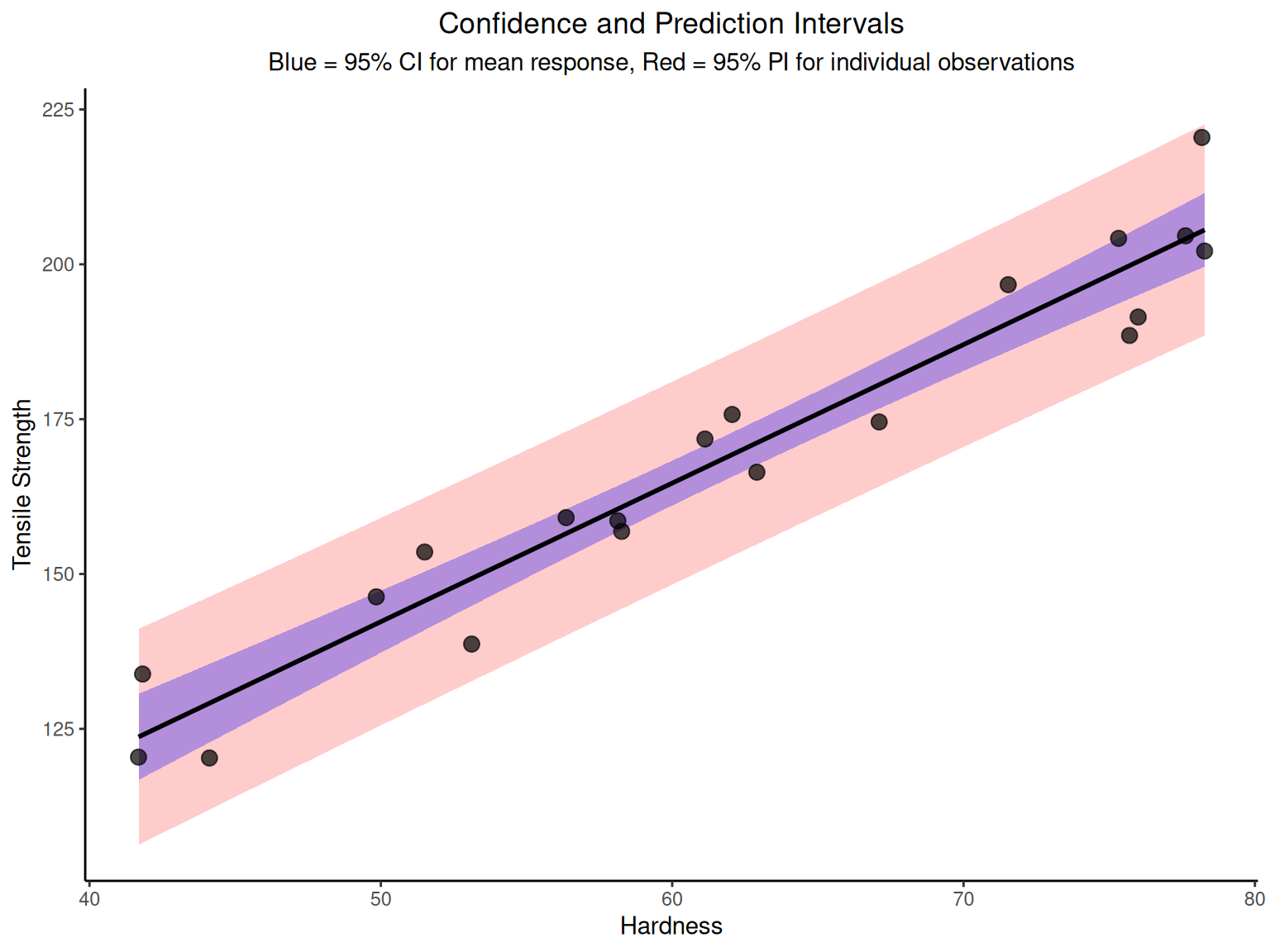
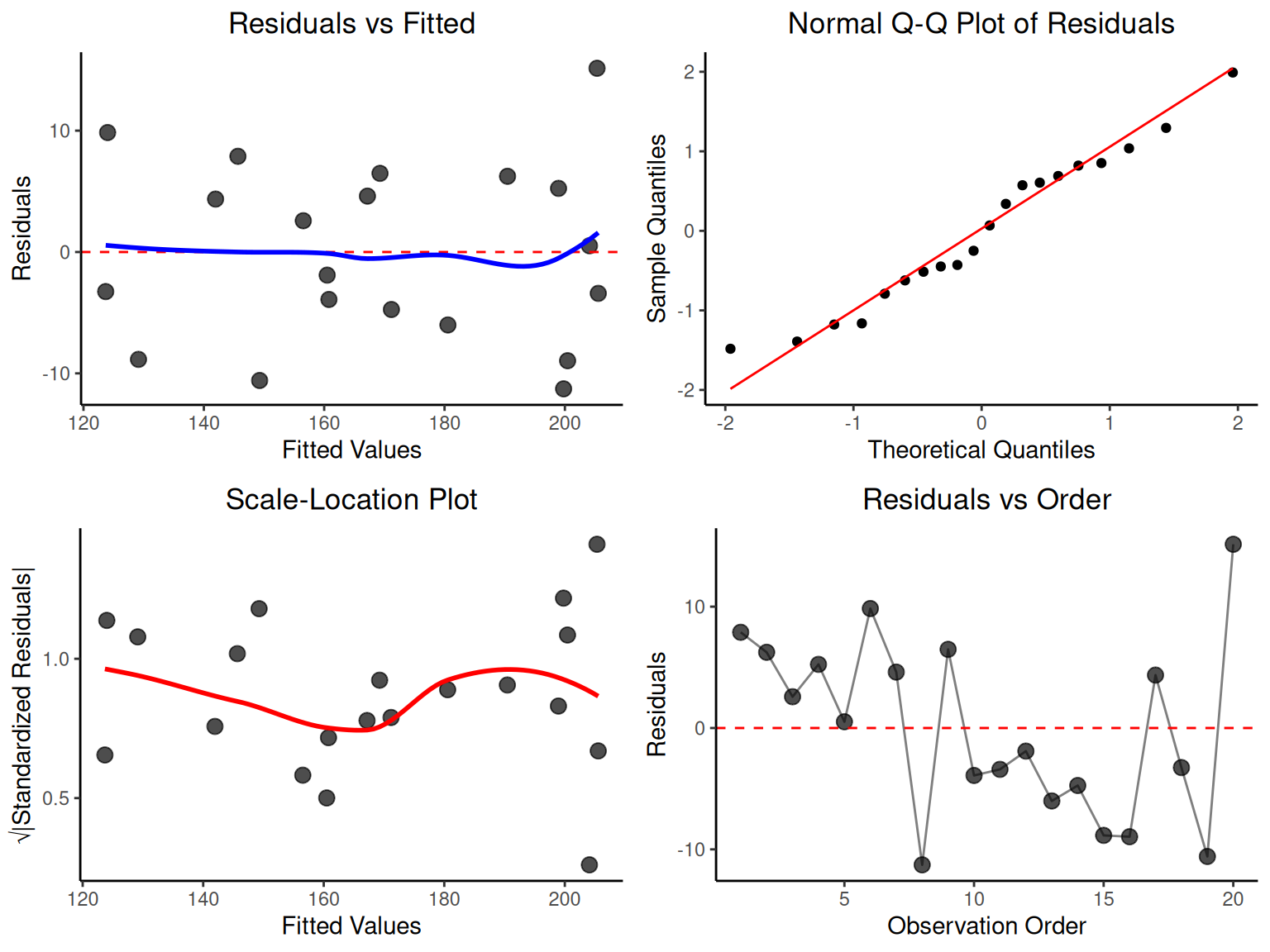
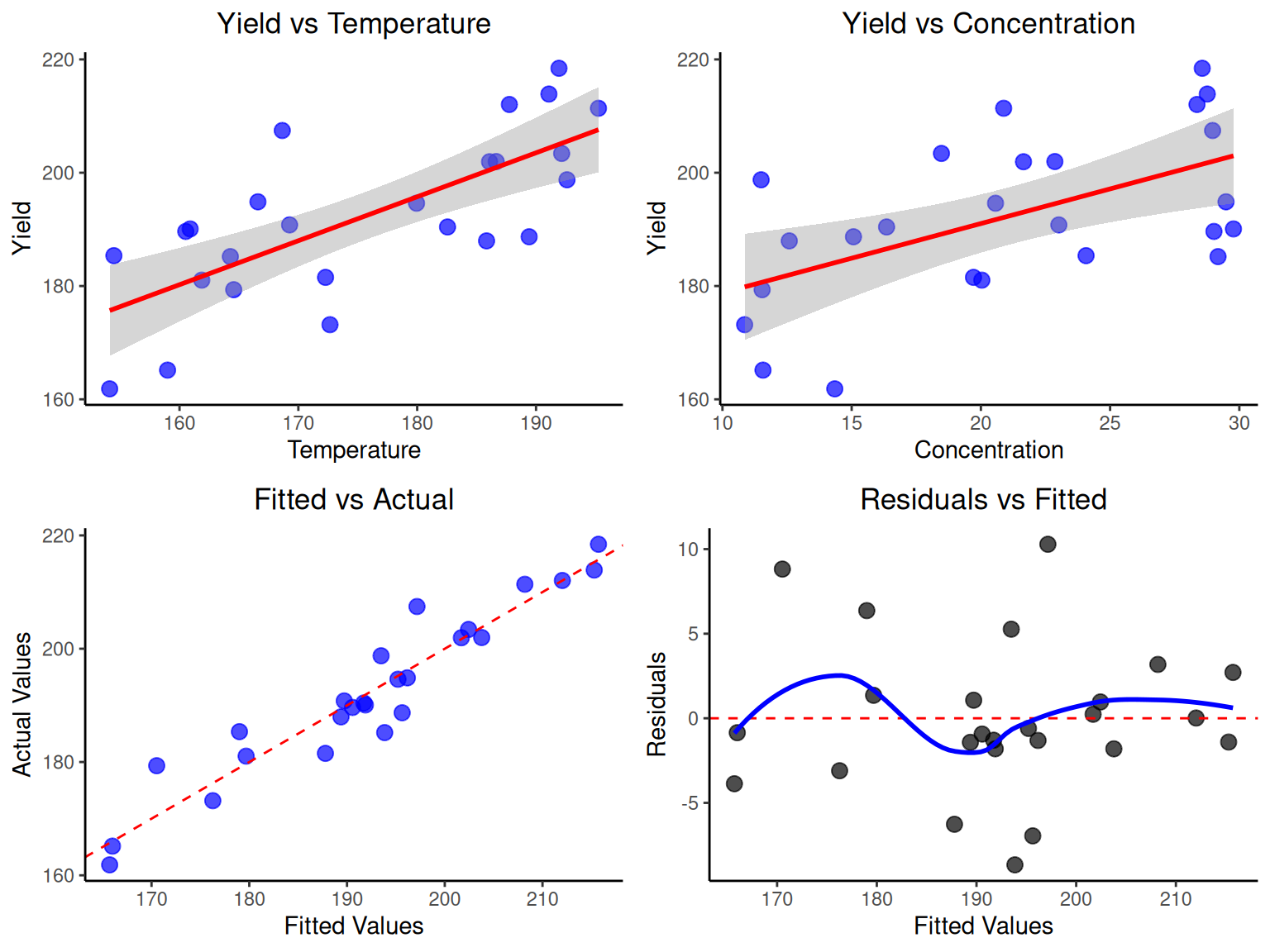
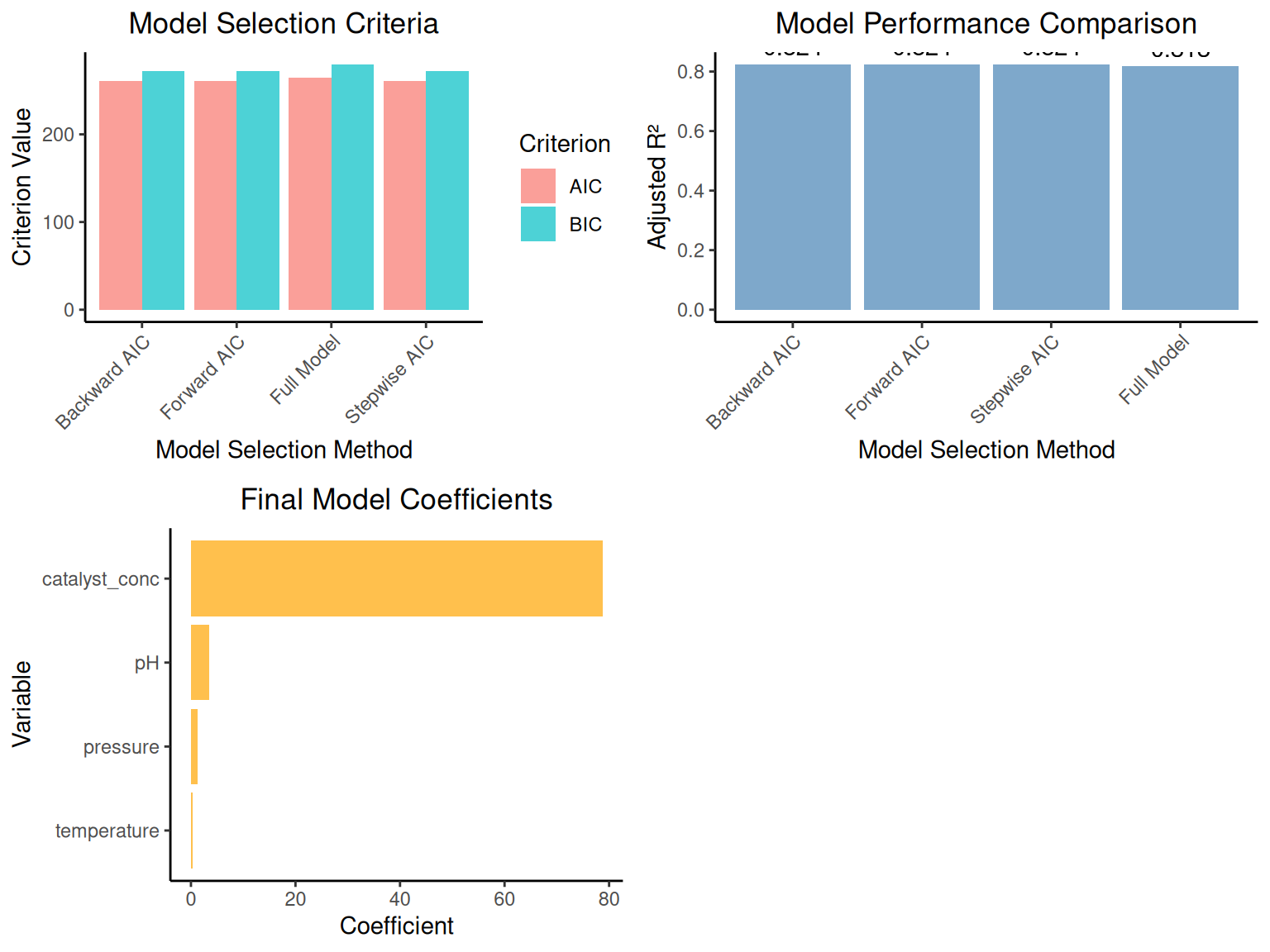
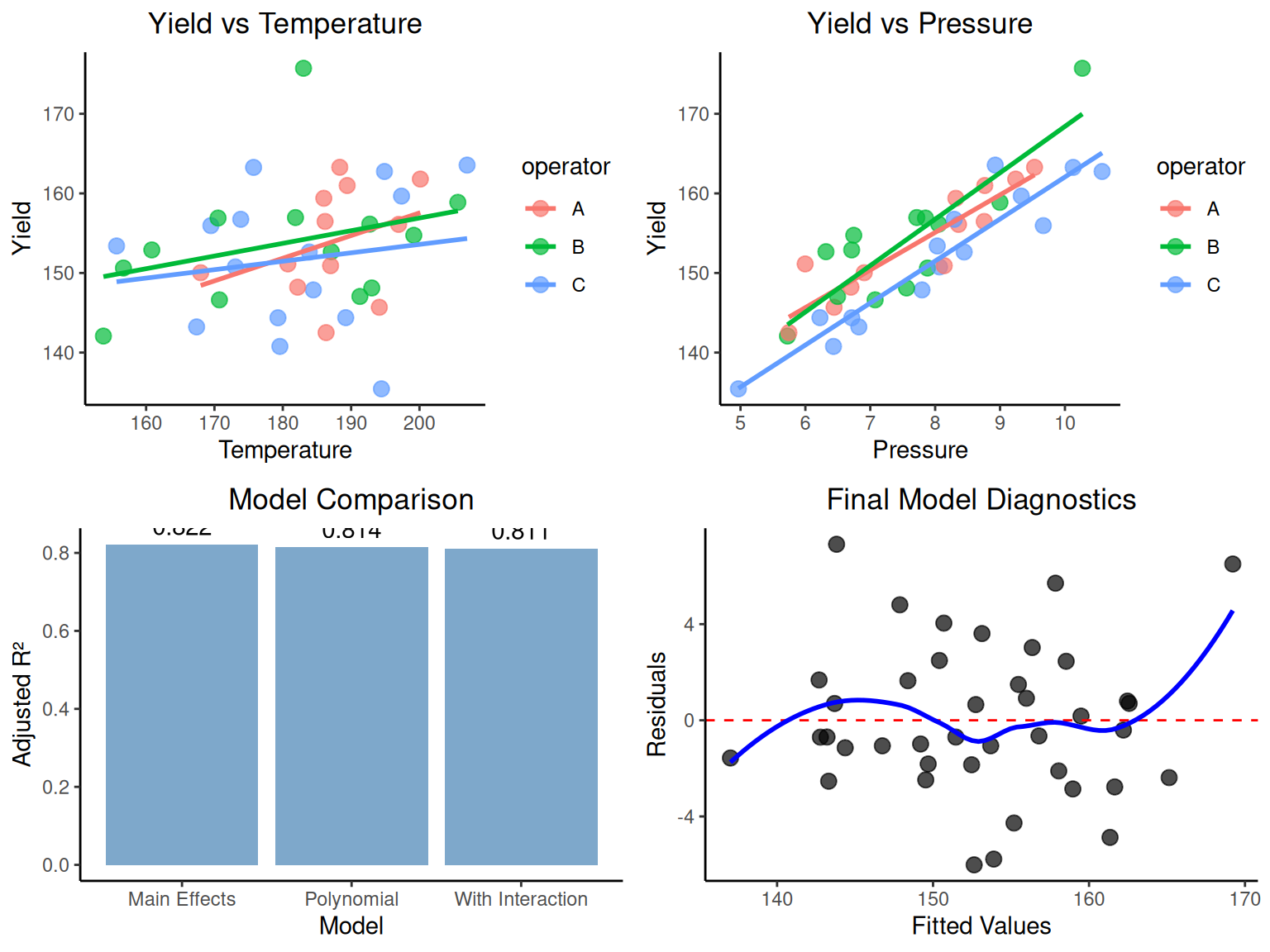
# Multiple regression inference
alpha_multi <- 0.05
t_critical_multi <- qt(1 - alpha_multi / 2, df_error_multi)
F_critical_multi <- qf(1 - alpha_multi, df_regression, df_error_multi)
# Overall F-test
F_stat_multi <- MSR_multi / MSE_multi
p_value_F_multi <- 1 - pf(F_stat_multi, df_regression, df_error_multi)
# Individual t-tests
t_stats <- c(
beta0_multi / SE_beta0_multi,
beta1_multi / SE_beta1_multi,
beta2_multi / SE_beta2_multi
)
p_values_t <- 2 * (1 - pt(abs(t_stats), df_error_multi))
# Hypothesis test results
hypothesis_tests_multi <- data.table(
Parameter = c("Overall Model", "β₀ (Intercept)", "β₁ (Temperature)", "β₂ (Concentration)"),
Test_Type = c("F-test", "t-test", "t-test", "t-test"),
Null_Hypothesis = c("β₁ = β₂ = 0", "β₀ = 0", "β₁ = 0", "β₂ = 0"),
Test_Statistic = c(round(F_stat_multi, 4), round(t_stats, 4)),
P_Value = c(round(p_value_F_multi, 4), round(p_values_t, 4)),
Decision = c(
ifelse(p_value_F_multi < alpha_multi, "Reject H₀", "Fail to reject H₀"),
ifelse(p_values_t < alpha_multi, "Reject H₀", "Fail to reject H₀")
),
Interpretation = c(
ifelse(p_value_F_multi < alpha_multi, "Model is significant", "Model not significant"),
ifelse(p_values_t[1] < alpha_multi, "Intercept significant", "Intercept not significant"),
ifelse(p_values_t[2] < alpha_multi, "Temperature effect significant", "Temperature not significant"),
ifelse(p_values_t[3] < alpha_multi, "Concentration effect significant", "Concentration not significant")
)
)
print("Multiple Regression Hypothesis Test Results:")
print(hypothesis_tests_multi)
# ANOVA table for multiple regression
anova_table_multi <- data.table(
Source = c("Regression", "Error", "Total"),
SS = c(round(SSR_multi, 2), round(SSE_multi, 2), round(SST_multi, 2)),
df = c(df_regression, df_error_multi, df_total),
MS = c(round(MSR_multi, 2), round(MSE_multi, 2), NA),
F_Statistic = c(round(F_stat_multi, 4), NA, NA),
P_Value = c(round(p_value_F_multi, 4), NA, NA)
)
print("Multiple Regression ANOVA Table:")
print(anova_table_multi)
# Confidence intervals for parameters
CI_multi <- data.table(
Parameter = c("β₀ (Intercept)", "β₁ (Temperature)", "β₂ (Concentration)"),
Estimate = c(beta0_multi, beta1_multi, beta2_multi),
Lower_95CI = c(
beta0_multi - t_critical_multi * SE_beta0_multi,
beta1_multi - t_critical_multi * SE_beta1_multi,
beta2_multi - t_critical_multi * SE_beta2_multi
),
Upper_95CI = c(
beta0_multi + t_critical_multi * SE_beta0_multi,
beta1_multi + t_critical_multi * SE_beta1_multi,
beta2_multi + t_critical_multi * SE_beta2_multi
)
)
print("95% Confidence Intervals for Parameters:")
print(round(CI_multi, 4))