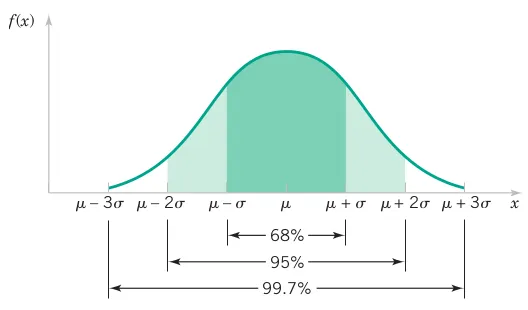
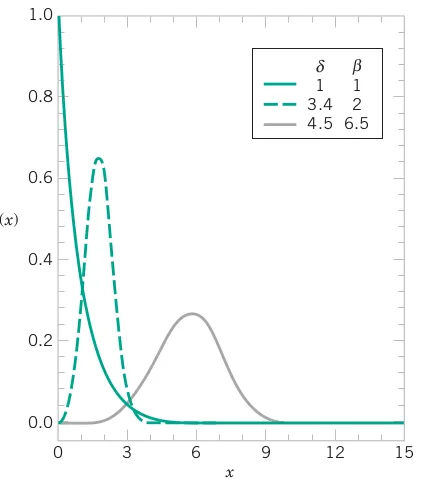
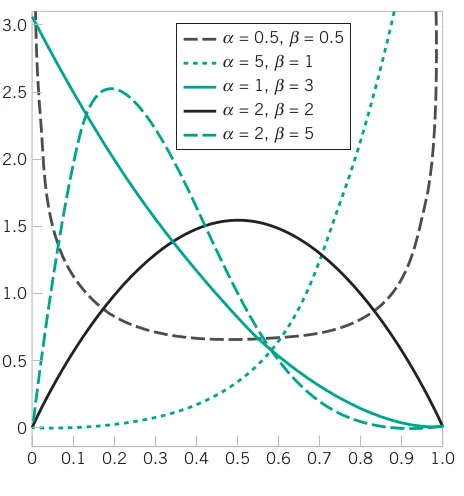
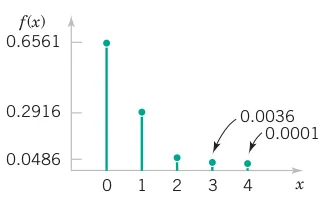
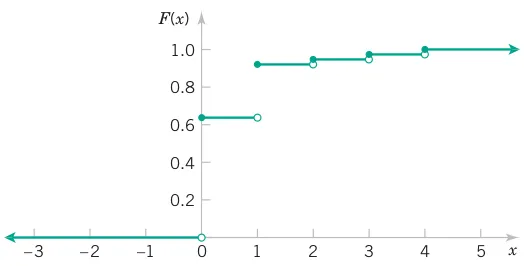
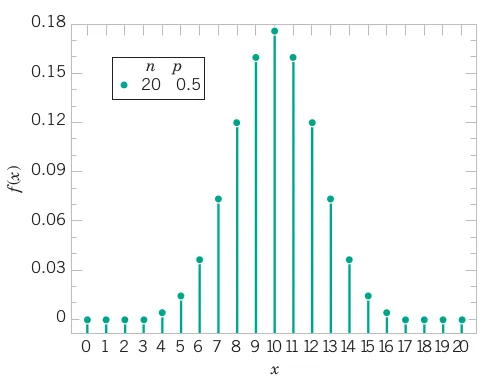
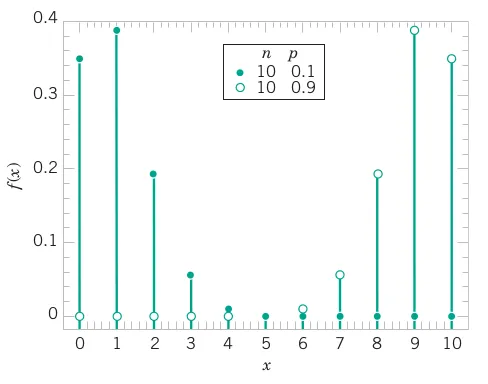
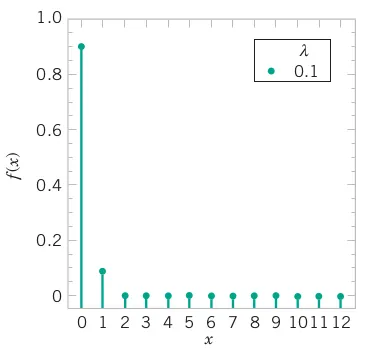
# Comprehensive Summary and Distribution Fitting Examples
library(fitdistrplus)
# Generate sample data for distribution fitting
set.seed(123)
# Example datasets
normal_sample <- rnorm(100, mean = 50, sd = 10)
exponential_sample <- rexp(100, rate = 0.1)
weibull_sample <- rweibull(100, shape = 2, scale = 100)
lognormal_sample <- rlnorm(100, meanlog = 4, sdlog = 0.5)
# Create comprehensive dataset
sample_data <- data.table(
normal_data = normal_sample,
exponential_data = exponential_sample,
weibull_data = weibull_sample,
lognormal_data = lognormal_sample
) %>%
fmutate(
observation = 1:fnobs(normal_data)
)
# Fit distributions using fitdistrplus
fit_normal <- fitdist(sample_data$normal_data, "norm")
fit_exponential <- fitdist(sample_data$exponential_data, "exp")
fit_weibull <- fitdist(sample_data$weibull_data, "weibull")
fit_lognormal <- fitdist(sample_data$lognormal_data, "lnorm")
# Summary statistics for each distribution
distribution_summary <- data.table(
distribution = c("Normal", "Exponential", "Weibull", "Lognormal"),
sample_mean = c(
fmean(sample_data$normal_data),
fmean(sample_data$exponential_data),
fmean(sample_data$weibull_data),
fmean(sample_data$lognormal_data)
),
sample_sd = c(
fsd(sample_data$normal_data),
fsd(sample_data$exponential_data),
fsd(sample_data$weibull_data),
fsd(sample_data$lognormal_data)
),
sample_min = c(
fmin(sample_data$normal_data),
fmin(sample_data$exponential_data),
fmin(sample_data$weibull_data),
fmin(sample_data$lognormal_data)
),
sample_max = c(
fmax(sample_data$normal_data),
fmax(sample_data$exponential_data),
fmax(sample_data$weibull_data),
fmax(sample_data$lognormal_data)
)
) %>%
fmutate(
sample_range = sample_max - sample_min,
cv = sample_sd / sample_mean
)
print("Distribution Summary Statistics:")
print(distribution_summary)
# Parameter estimates
param_estimates <- data.table(
distribution = c("Normal", "Exponential", "Weibull", "Lognormal"),
param1_name = c("mean", "rate", "shape", "meanlog"),
param1_estimate = c(
fit_normal$estimate[1],
fit_exponential$estimate[1],
fit_weibull$estimate[1],
fit_lognormal$estimate[1]
),
param2_name = c("sd", NA, "scale", "sdlog"),
param2_estimate = c(
fit_normal$estimate[2],
NA,
fit_weibull$estimate[2],
fit_lognormal$estimate[2]
)
)
print("Parameter Estimates:")
print(param_estimates)
# Goodness of fit tests
gof_tests <- data.table(
distribution = c("Normal", "Exponential", "Weibull", "Lognormal"),
ks_statistic = c(
ks.test(sample_data$normal_data, "pnorm",
mean = fit_normal$estimate[1], sd = fit_normal$estimate[2]
)$statistic,
ks.test(sample_data$exponential_data, "pexp",
rate = fit_exponential$estimate[1]
)$statistic,
ks.test(sample_data$weibull_data, "pweibull",
shape = fit_weibull$estimate[1], scale = fit_weibull$estimate[2]
)$statistic,
ks.test(sample_data$lognormal_data, "plnorm",
meanlog = fit_lognormal$estimate[1], sdlog = fit_lognormal$estimate[2]
)$statistic
),
ks_p_value = c(
ks.test(sample_data$normal_data, "pnorm",
mean = fit_normal$estimate[1], sd = fit_normal$estimate[2]
)$p.value,
ks.test(sample_data$exponential_data, "pexp",
rate = fit_exponential$estimate[1]
)$p.value,
ks.test(sample_data$weibull_data, "pweibull",
shape = fit_weibull$estimate[1], scale = fit_weibull$estimate[2]
)$p.value,
ks.test(sample_data$lognormal_data, "plnorm",
meanlog = fit_lognormal$estimate[1], sdlog = fit_lognormal$estimate[2]
)$p.value
)
) %>%
fmutate(
good_fit = ks_p_value > 0.05
)
print("Goodness of Fit Tests:")
print(gof_tests)
# Save all datasets
fwrite(sample_data, "data/distribution_samples.csv")
fwrite(distribution_summary, "data/distribution_summary.csv")
fwrite(param_estimates, "data/parameter_estimates.csv")
fwrite(gof_tests, "data/goodness_of_fit.csv")