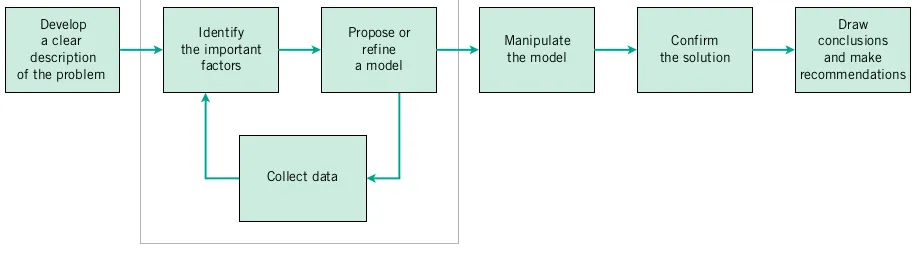
Engineering Context: An engineer is developing a rubber compound for use in O-rings. The O-rings are to be employed as seals in plasma etching tools used in the semiconductor industry, so their resistance to acids and other corrosive substances is an important characteristic.
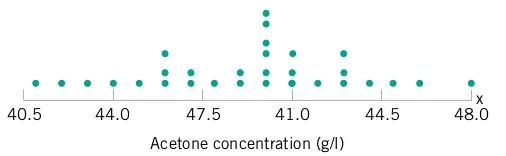
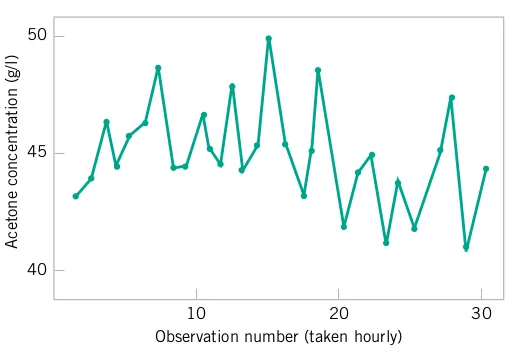
The engineer uses the standard rubber compound to produce eight O-rings in a development laboratory and measures the tensile strength of each specimen after immersion in a nitric acid solution at 30°C for 25 minutes. The tensile strengths (in psi) of the eight O-rings are 1030, 1035, 1020, 1049, 1028, 1026, 1019, and 1010.
O-Ring Sample Statistics & Confidence Interval
| 8 |
1027.1 |
1027 |
11.7 |
1010 |
1049 |
4.14 |
2.36 |
9.8 |
1017.3 |
1036.9 |
Analysis:
Population: All possible O-rings made with this rubber compound
Sample: The eight O-rings tested (n = 8)
Parameter: True mean tensile strength (μ) of all O-rings
Statistic: Sample mean tensile strength (x̄ = 1027.1 psi)
As we should have anticipated, not all the O-ring specimens exhibit the same measurement of tensile strength.