We illustrate the recommended layout for data sheets with one of the trials conducted by the Australian Centre for International Agricultural Research (ACIAR) in Queensland, Australia (Experiment 309). This was a species trial planted in 1985; survival was poor. For our example we will examine only part of the data from this experiment. Five of the species with good survival have been extracted at random, namely Acacia, Angophora, Casuarina, Melaleuca and Petalostigma.
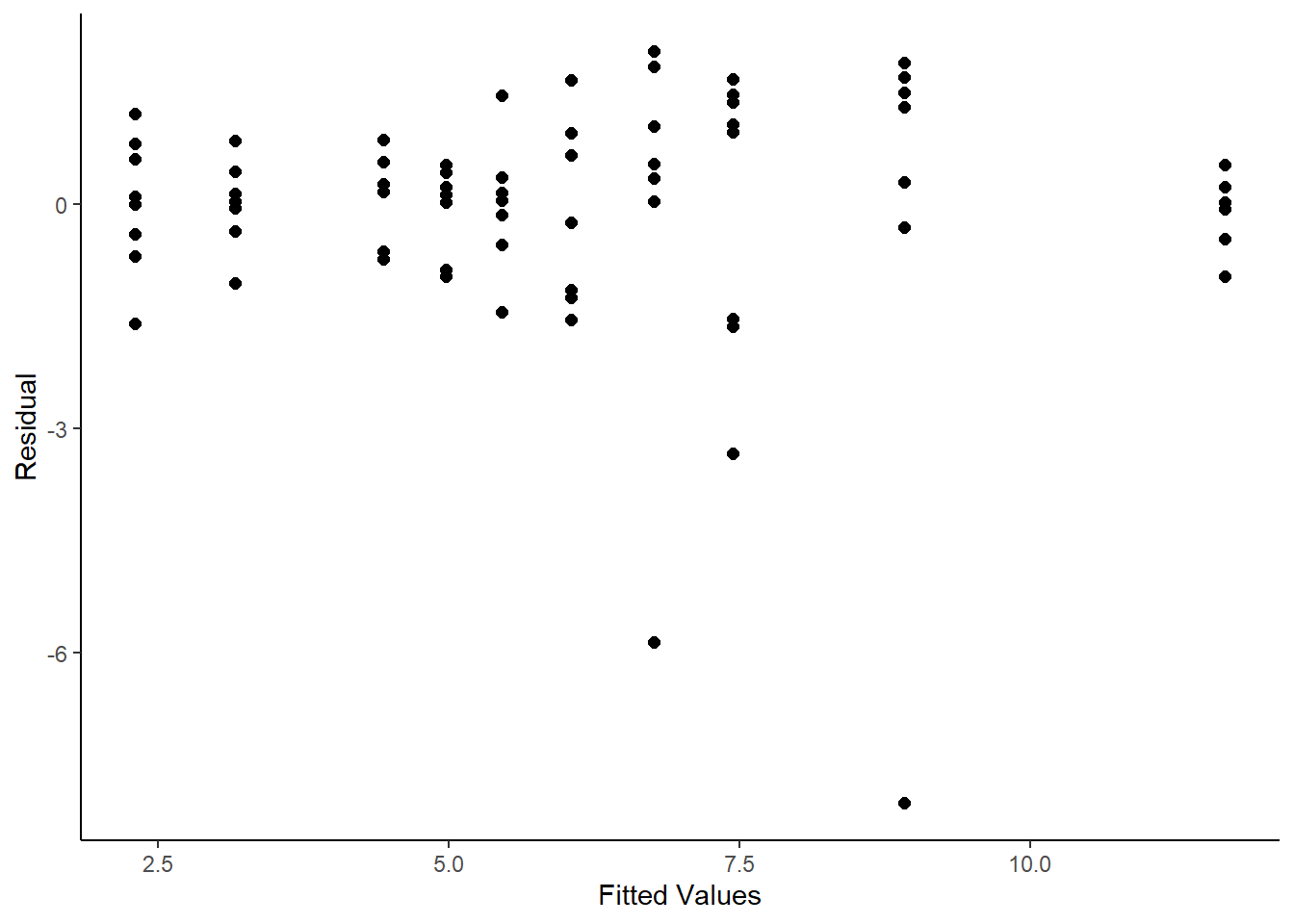
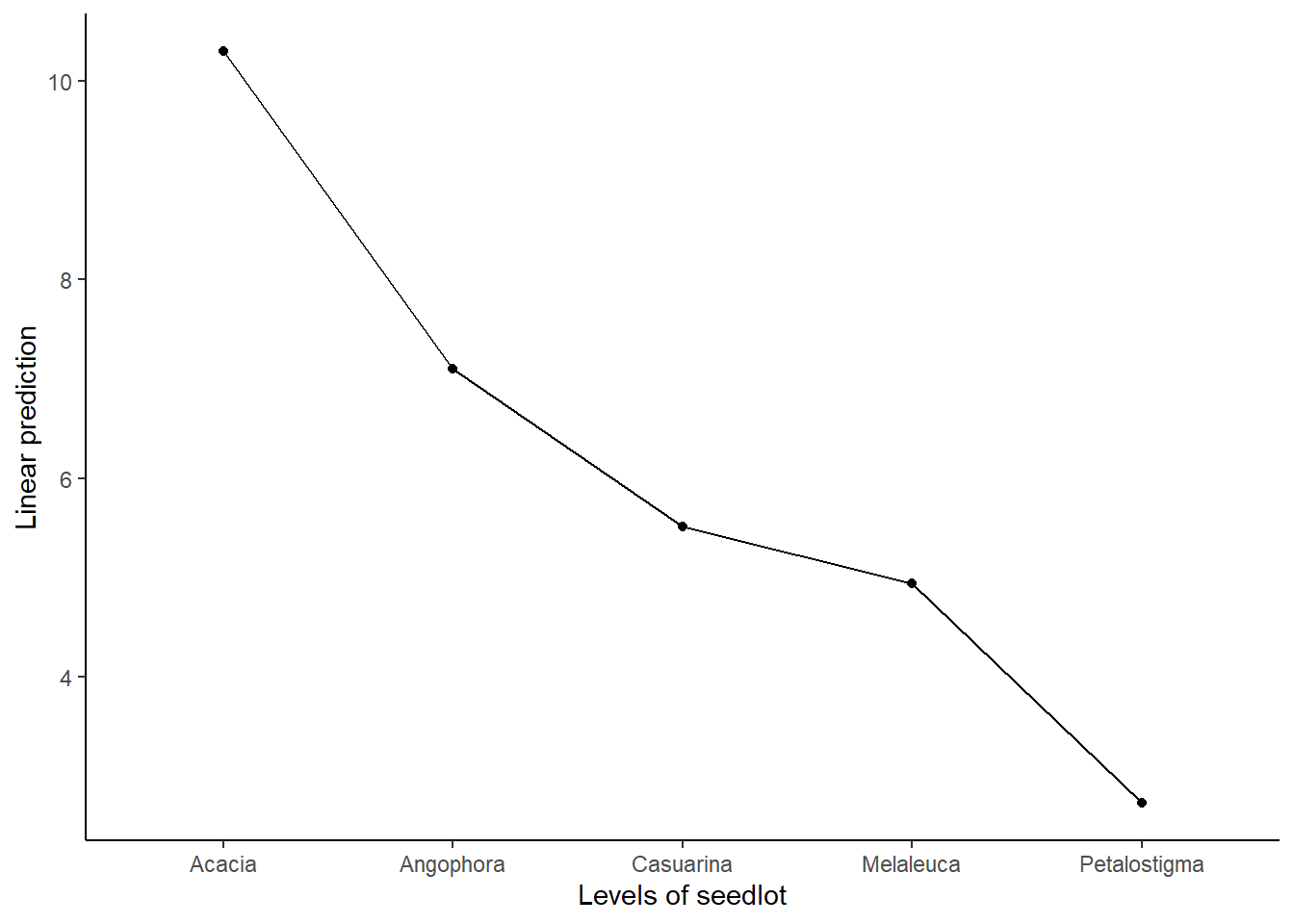
library(car)library(dae)library(dplyr)library(emmeans)library(ggplot2)library(lmerTest)library(magrittr)library(predictmeans)library(supernova)data(DataExam3.1)# Pg. 28 fmtab3.3<-lm(formula = ht ~ repl*seedlot , data = DataExam3.1 ) fmtab3.3ANOVA1 <-anova(fmtab3.3) %>%mutate("F value"=c(anova(fmtab3.3)[1:2, 3]/anova(fmtab3.3)[3, 3] , anova(fmtab3.3)[3, 4] , NA ) )# Pg. 33 (Table 3.3) fmtab3.3ANOVA1 %>%mutate("Pr(>F)"=c(NA , pf(q = fmtab3.3ANOVA1[2, 4] , df1 = fmtab3.3ANOVA1[2, 1] , df2 = fmtab3.3ANOVA1[3, 1], lower.tail =FALSE ) , NA , NA ) ) Df Sum Sq Mean Sq F value Pr(>F) repl 120.3020.3013.4197seedlot 4505.87126.46721.30350.005851**repl:seedlot 423.755.9362.3663Residuals 70175.612.509---Signif. codes:0'***'0.001'**'0.01'*'0.05'.'0.1' '1# Pg. 33 (Table 3.3)emmeans(object = fmtab3.3, specs =~ seedlot) seedlot emmean SE df lower.CL upper.CL Acacia 10.290.396709.5011.08 Angophora 7.100.396706.317.89 Casuarina 5.510.396704.726.30 Melaleuca 4.940.396704.155.73 Petalostigma 2.730.396701.943.52Results are averaged over the levels of: repl Confidence level used:0.95# Pg. 34 (Figure 3.2)ggplot(mapping =aes(x =fitted.values(fmtab3.3) , y =residuals(fmtab3.3) ) ) +geom_point(size =2) +labs(x ="Fitted Values" , y ="Residual" ) +theme_classic()