[1] 4[1] 3[1] 10[1] 3[1] 4[1] 8[1] 5[1] 3.14BMI: 3.4 Welcome to the exciting world of data analysis! This comprehensive guide will teach you three essential tools that work together to make data analysis both powerful and accessible:
R: A free, open-source programming language specifically designed for statistics and data analysis
RStudio: A user-friendly integrated development environment (IDE) that makes working with R much easier
Quarto: A modern publishing system that allows you to create professional reports, presentations, and websites
These tools form a complete ecosystem for modern data science, allowing you to import data, analyze it, create visualizations, and share your findings in professional documents (Posit Team 2022).
The combination of R, RStudio, and Quarto offers several compelling advantages for beginners and professionals alike (Wickham and Grolemund 2016; Posit Team 2023):
Completely Free: All three tools are open-source and free to use, with no licensing fees or subscription costs
Beginner-Friendly: Despite their power, these tools are designed with simple commands and intuitive interfaces
Professional Results: Create publication-ready charts, statistical analyses, and formatted reports (Wickham 2016)
Widely Used: Millions of data scientists, researchers, and analysts worldwide use these tools daily
Great Community: Large, helpful community with extensive tutorials, documentation, and support
Reproducible Research: Your analysis can be easily shared and reproduced by others (Allaire et al. 2022)
Versatile: Suitable for everything from simple calculations to complex statistical modeling
R is much more than just a calculator—it’s a complete statistical computing environment. Originally developed by statisticians for statisticians, R has evolved into one of the world’s most popular tools for data analysis. Think of R as:
A powerful calculator that can handle complex mathematical operations
A data management system that can work with datasets of any size
A graphics engine that creates beautiful, publication-ready charts
A programming language that can automate repetitive tasks
A statistical toolkit with thousands of specialized functions
R is particularly valuable because it’s designed specifically for working with data, making tasks that are difficult in other software surprisingly straightforward.
Getting R installed on your computer is straightforward:
Visit the official website: Go to https://cran.r-project.org/
Choose your operating system: Click on “Download R for Windows,” “Download R for macOS,” or “Download R for Linux”
Download the latest version: Always choose the most recent version (usually at the top of the list)
Run the installer: Use default settings unless you have specific requirements
Verify installation: Open R to make sure it starts correctly
The CRAN (Comprehensive R Archive Network) website is the official and safest place to download R. Avoid downloading from other websites to ensure you get an authentic, virus-free version.
Let’s start with the fundamentals. R can perform all standard mathematical operations and much more. Notice how we use clear argument names to make our code easy to understand:
[1] 4[1] 3[1] 10[1] 3[1] 4[1] 8[1] 5[1] 3.14BMI: 3.4 As you can see, R can handle basic arithmetic effortlessly. The cat() function helps us display results clearly. Using explicit argument names like x = and digits = makes your code much easier to read and understand, especially when you’re learning.
One of the most important concepts in data analysis is working with structured data. We’ll use the powerful data.table package along with fastverse and tidyverse for efficient data operations:
# Load all required packages for this tutorial
library(data.table) # Fast data manipulation and file reading
library(fastverse) # Collection of fast R packages for data science
library(tidyverse) # Collection of packages for data science workflow
library(readxl) # Read Excel files (.xlsx, .xls)
library(openxlsx) # Write Excel files and advanced Excel operations
library(knitr) # Dynamic report generation and table formatting
library(ggplot2) # Advanced data visualization (part of tidyverse)All the packages we need for this tutorial are loaded in the setup chunk above. This keeps our code organized and ensures everything is available when we need it.
name age grade major
<char> <num> <num> <char>
1: Alice 20 85 Math
2: Bob 22 92 Physics
3: Charlie 21 78 Chemistry
4: Diana 23 88 BiologyClasses 'data.table' and 'data.frame': 4 obs. of 4 variables:
$ name : chr "Alice" "Bob" "Charlie" "Diana"
$ age : num 20 22 21 23
$ grade: num 85 92 78 88
$ major: chr "Math" "Physics" "Chemistry" "Biology"
- attr(*, ".internal.selfref")=<externalptr> The data.table package offers several advantages over base R (Dowle and Srinivasan 2023):
Faster performance: Especially noticeable with larger datasets
More intuitive syntax: Operations often feel more natural
Memory efficient: Uses less computer memory
Better for beginners: Clearer error messages and more predictable behavior
Now that we have some data, let’s calculate basic statistics using the efficient fastverse functions. These functions are faster and more consistent than base R functions:
avg_age avg_grade max_grade min_grade
<num> <num> <num> <num>
1: 21.5 85.75 92 78 n_students age_range grade_range grade_sd
<int> <char> <char> <num>
1: 4 20 to 23 78 to 92 5.91Understanding these basic statistics is crucial:
Mean (Average): The sum of all values divided by the number of values
Maximum/Minimum: The highest and lowest values in your data
Standard Deviation: How spread out your data points are
Count: The number of observations in your dataset
Notice how we use fmean(), fmax(), fmin(), and other fast functions from the fastverse package. These are more efficient than the base R equivalents.
One of R’s greatest strengths is creating high-quality visualizations. The ggplot2 package (Wickham 2016) makes this process both powerful and intuitive. We’ll also learn how to save our plots:
# Create visualization (ggplot2 already loaded)
p1 <-
ggplot(data = students, mapping = aes(x = name, y = grade, fill = major)) +
geom_col() +
labs(title = "Student Grades by Major", x = "Student", y = "Grade", fill = "Major") +
theme_minimal() +
theme(plot.title = element_text(hjust = 0.5))
# Display the plot
p1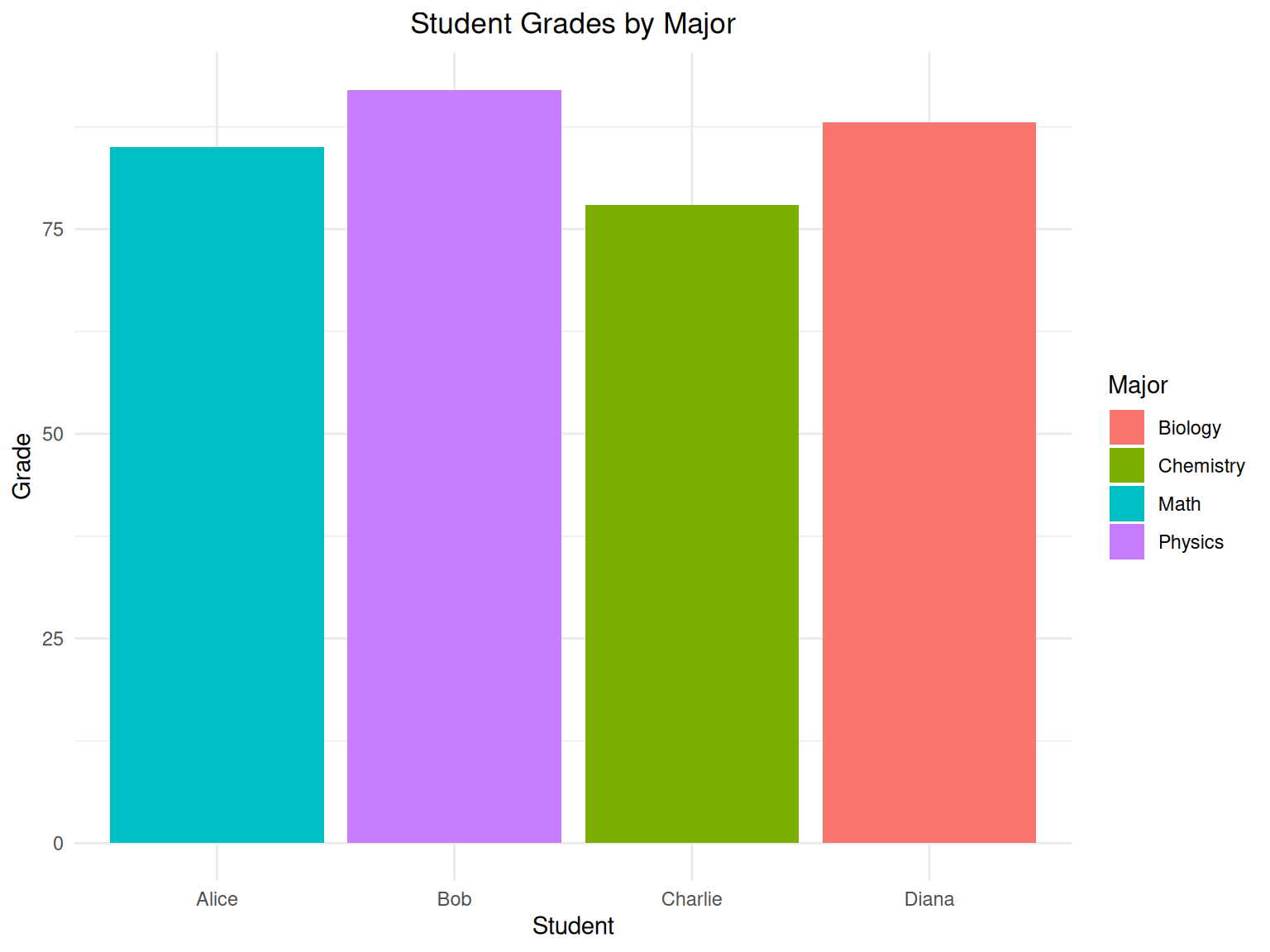
This chart immediately shows us that Bob has the highest grade (92) and Charlie has the lowest (78). Visualizations like this make patterns in data much easier to spot than looking at numbers alone.
Notice how we:
Store the plot in a variable (p1) before displaying it
Use explicit argument names in ggplot() like data = and mapping =
Save the plot for future use or sharing
While you can use R by itself, RStudio (Posit Team 2023) makes the experience much more pleasant and productive. RStudio is an Integrated Development Environment (IDE) that provides a user-friendly interface for R.
RStudio organizes your work into four main areas:
Script Editor (top-left): Where you write and edit your R code
Syntax highlighting makes code easier to read
Auto-completion helps you write code faster
You can save your scripts for later use
Console (bottom-left): Where you interact directly with R
Type commands and see immediate results
View error messages and warnings
Test code snippets quickly
Environment/History (top-right): Shows your current workspace
Environment tab: See all your data objects and variables
History tab: Review commands you’ve run previously
Connections tab: Manage database connections
Files/Plots/Packages/Help (bottom-right): Multiple useful tabs
Files tab: Navigate your computer’s file system
Plots tab: View charts and graphs you create
Packages tab: Install and manage R packages
Help tab: Access documentation and tutorials
RStudio installation is straightforward, but R must be installed first:
Ensure R is installed: RStudio requires R to be installed first
Visit Posit: Go to https://posit.co/downloads/
Choose RStudio Desktop: The free version is perfect for learning
Download and install: Follow the installation wizard with default settings
Launch RStudio: You should see the four-panel interface
One of RStudio’s best features is project management. Projects keep your work organized and make it easy to switch between different analyses:
Organization: Keep related files together
Working Directory: Automatically sets the correct folder
Portability: Easy to share entire projects with others
Version Control: Integrate with Git for tracking changes
# Create directories
dirs <- c("data", "figures", "R", "out")
sapply(dirs, dir.create, showWarnings = FALSE)
# Sample data (data.table already loaded)
sales <-
data.table(
month = c("Jan", "Feb", "Mar", "Apr", "May", "Jun"),
sales = c(100, 120, 150, 130, 160, 180),
region = rep(c("North", "South"), 3)
)
# Export files (packages already loaded)
fwrite(x = sales, file = "data/sales.csv")
write.xlsx(x = sales, file = "data/sales.xlsx")
cat("Files created:\n")
list.files(path = "data", full.names = TRUE)When you create a project, RStudio:
Creates a dedicated folder for your work
Sets up the proper working directory
Remembers your project settings
Makes it easy to share your work with others
Notice how we create an “out” folder to store our output files and saved plots.
Quarto (Allaire et al. 2022) represents the next generation of scientific and technical publishing. It’s a powerful system that allows you to combine code, text, and outputs into professional documents. Think of Quarto as a way to create reports that include:
Your analysis code: So others can see exactly what you did
Results and charts: Automatically generated from your code
Written explanations: Your insights and conclusions
Professional formatting: Ready for sharing or publication
Traditional data analysis often involves:
Analyzing data in one program
Creating charts in another program
Writing conclusions in a word processor
Manually copying results between programs
This approach has problems:
Error-prone: Easy to copy wrong numbers
Time-consuming: Updates require changing multiple files
Not reproducible: Others can’t verify your work
Quarto solves these problems by combining everything in one document that automatically updates when your data or analysis changes.
Quarto installation is simple and integrates seamlessly with RStudio:
Visit the official website: Go to https://quarto.org/docs/get-started/
Download for your system: Choose Windows, macOS, or Linux
Install with defaults: The installer will handle everything
Restart RStudio: This enables Quarto integration
Verify installation: You should see Quarto options in RStudio menus
Quarto projects provide additional organization and publishing features beyond basic RStudio projects:
In RStudio:
File → New Project
New Directory
Quarto Project
Choose project type (Document, Website, Book, etc.)
Configure options (output formats, features)
Create Project
Multiple output formats: HTML, PDF, Word from the same source
Consistent styling: Professional appearance across all outputs
Cross-references: Automatic numbering for figures and tables
Bibliography management: Automatic citation formatting
Website publishing: Easy deployment to GitHub Pages or other platforms
The process is straightforward in RStudio:
File → New File → Quarto Document
Enter document details: Title, author, output format
Choose format: HTML is best for beginners
Click Create: RStudio opens a template document
Every Quarto document has three main parts:
YAML Header: Configuration between --- lines
Text: Written in Markdown format
Code Chunks: R code between ```{r} and ```
Quarto’s ability to create multiple formats from one source is powerful:
Best for: Interactive sharing, online viewing
Features: Can include interactive elements, easy to share via email or web
Best for: Professional reports, academic papers
Features: Page numbers, professional typography, print-ready
Best for: Collaborating with non-R users
Features: Compatible with Microsoft Word, easy editing by others
Let’s create a complete example that demonstrates Quarto’s capabilities using fastverse functions:
# Weather data
weather <-
data.table(
day = c("Mon", "Tue", "Wed", "Thu", "Fri"),
temp = c(22, 25, 23, 27, 24),
humidity = c(60, 55, 65, 50, 58),
condition = c("Sunny", "Cloudy", "Rainy", "Sunny", "Partly Cloudy")
)
# Statistics with pipe and fastverse
weather %>%
fsummarise(
avg_temp = fmean(temp),
max_temp = fmax(temp),
min_temp = fmin(temp)
) avg_temp max_temp min_temp
<num> <num> <num>
1: 24.2 27 22# Create and save visualization
p2 <- ggplot(data = weather, mapping = aes(x = day, y = temp, fill = condition)) +
geom_col() +
labs(title = "Daily Temperature", x = "Day", y = "Temperature (°C)", fill = "Condition") +
theme_minimal() +
geom_text(mapping = aes(label = paste(temp, "°C")), vjust = -0.3)
# Display the plot
p2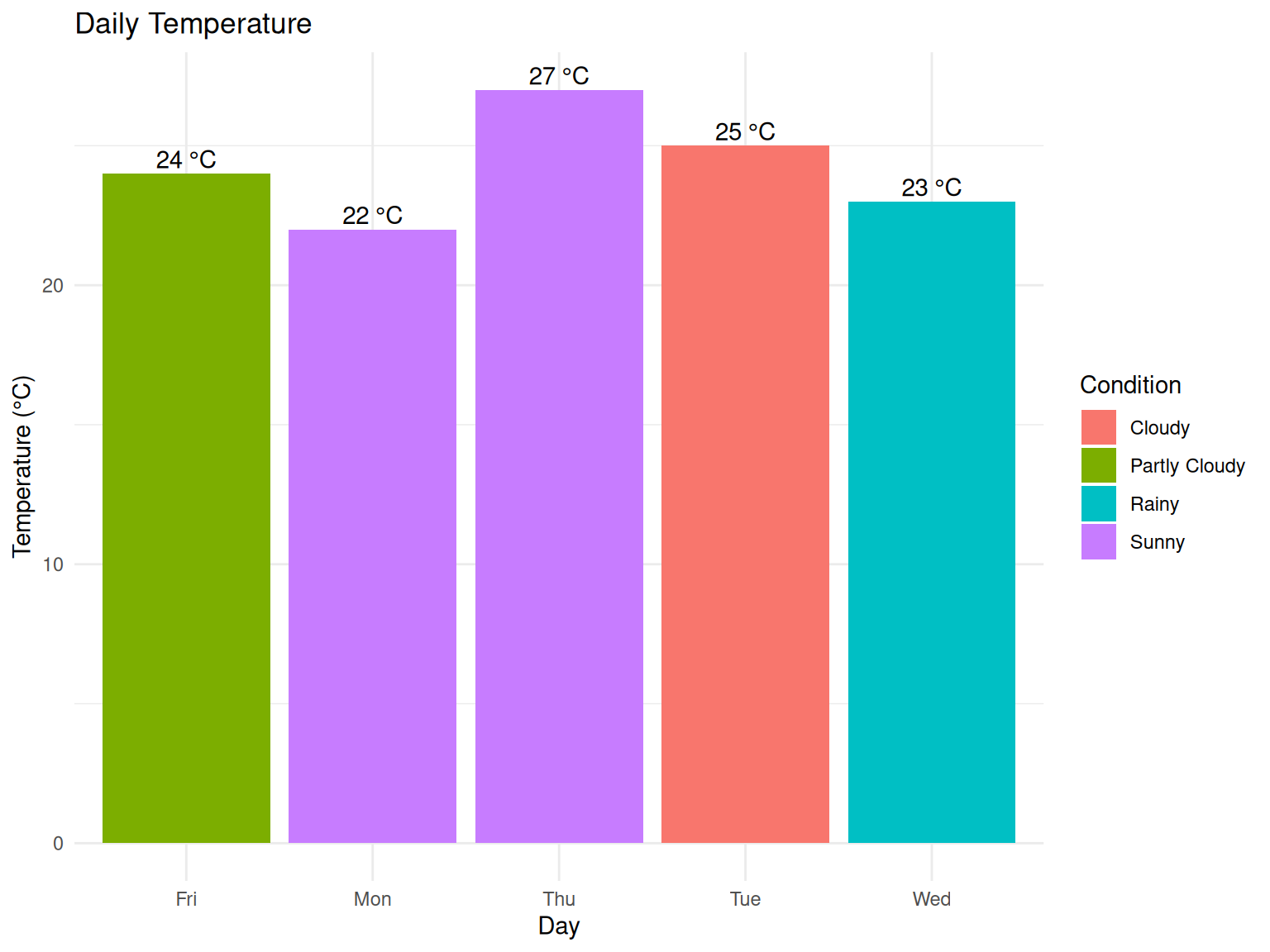
This example demonstrates several key Quarto features:
Code execution: The R code runs automatically
Output capture: Results are included in the document
Figure generation: Charts are created and properly captioned
Professional formatting: Everything looks polished
Notice how we use fmean(), fmax(), and fmin() from fastverse for efficient statistical calculations.
Modern data analysis often involves working with data stored in various formats. Here’s how to handle the most common ones using efficient functions:
# Read data efficiently with explicit arguments (packages already loaded)
sales_csv <- fread(file = "data/sales.csv")
sales_excel <- read_excel(path = "data/sales.xlsx") %>% as.data.table()
# Compare datasets
identical(x = sales_csv, y = sales_excel)
rbindlist(l = list(CSV = sales_csv, Excel = sales_excel), idcol = "Source")CSV files: Plain text, widely compatible, smaller file size
Excel files: Can contain multiple sheets, formatted data, larger file size
data.table: More efficient than data.frame for larger datasets
Notice how we use fread() instead of read.csv() - it’s much faster and more flexible.
Let’s work through some realistic examples that demonstrate common data analysis tasks using fastverse functions:
| student | math | english | science |
|---|---|---|---|
| Anna | 85 | 88 | 82 |
| Bob | 92 | 85 | 90 |
| Carol | 78 | 92 | 85 |
| David | 88 | 80 | 92 |
| Eva | 95 | 90 | 88 |
| Subject | Average |
|---|---|
| Math | 87.6 |
| English | 87.0 |
| Science | 87.4 |
This table shows our data in a clean, professional format that’s easy to read and understand.
Now let’s create a comparison visualization:
# Reshape data for visualization
subject_avg <-
scores %>%
fsummarise(
Math = fmean(math),
English = fmean(english),
Science = fmean(science)
) %>%
pivot(
how = "longer",
names = list("Subject", "Average")
)
# Create and save comparison chart
p3 <- ggplot(data = subject_avg, mapping = aes(x = Subject, y = Average, fill = Subject)) +
geom_col(alpha = 0.8, show.legend = FALSE) +
labs(title = "Average Test Scores by Subject", x = "Subject", y = "Average Score") +
theme_minimal() +
geom_text(mapping = aes(label = round(x = Average, digits = 1)), vjust = -0.3) +
ylim(0, 100)
# Display the plot
p3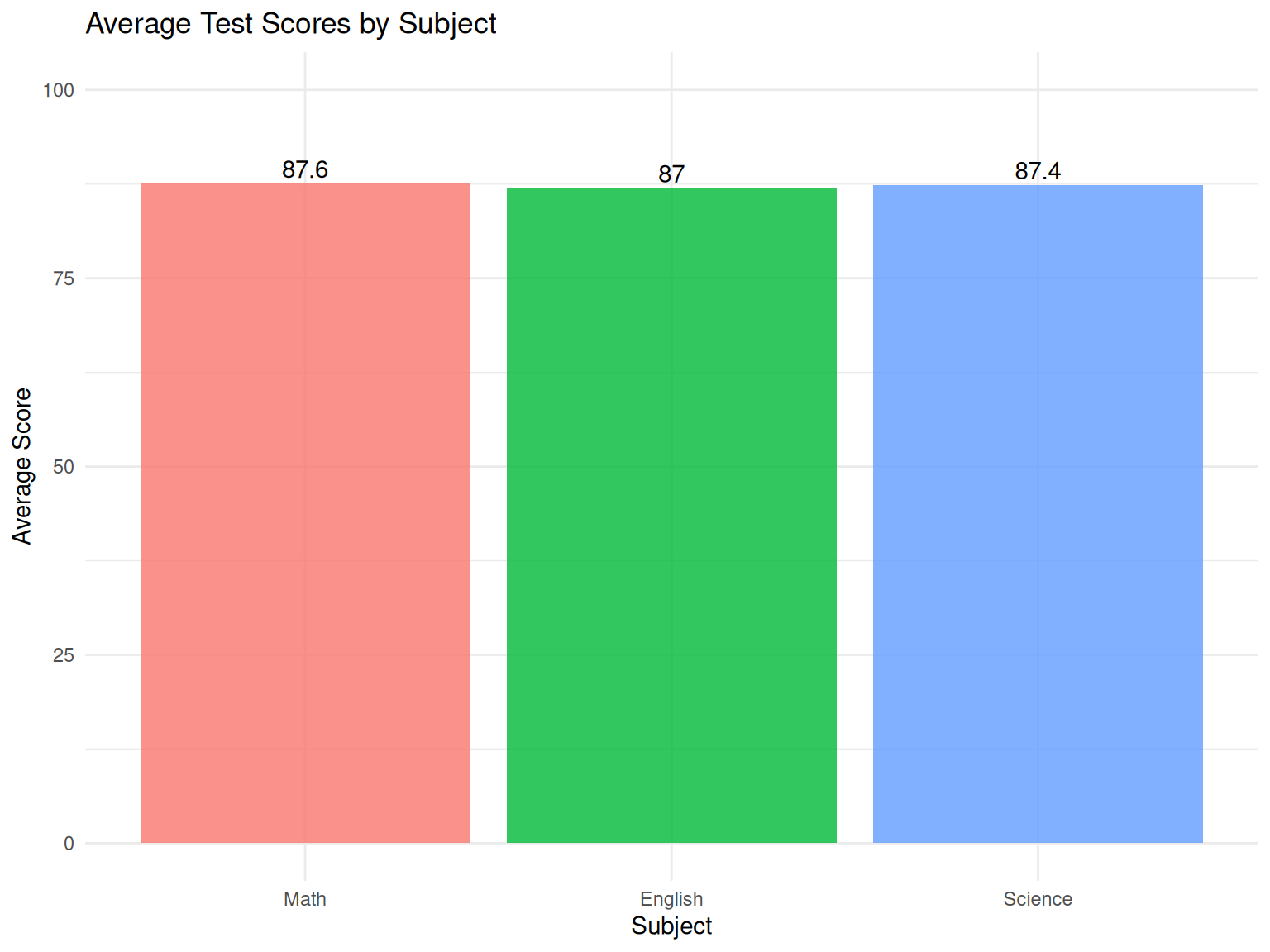
This visualization immediately shows that Math scores are slightly higher than English scores on average, demonstrating how charts can reveal patterns that might not be obvious from tables alone.
Notice how we use:
fmean() for calculating averages efficiently
pivot() for reshaping data
Explicit argument names throughout for clarity
Learning R is a journey, and everyone needs help sometimes. Here are the best ways to get assistance:
RStudio Help pane: Built-in documentation with examples
Stack Overflow: Huge community of R users answering questions
R-bloggers: Daily articles about R techniques and applications
Local R User Groups: Many cities have R meetups and workshops
Learning from common mistakes can save you hours of frustration:
R distinguishes between uppercase and lowercase letters:
Mean ≠ mean (only mean is the correct function)
Data ≠ data (variable names must match exactly)
Text must be enclosed in quotes:
Correct: "Alice", "Sales Department"
Incorrect: Alice, Sales Department
Packages must be loaded before use:
Always run library(fastverse) before using fastverse functions
Load packages at the beginning of your script
Every opening parenthesis needs a closing one:
fmean(students$age) ✓
fmean(students$age ✗ (missing closing parenthesis)
Always use explicit argument names when learning:
Good: round(x = 3.14159, digits = 2)
Less clear: round(3.14159, 2)
Learning these shortcuts will significantly speed up your work:
Ctrl+Enter (Windows) or Cmd+Enter (Mac): Run current line or selection
Ctrl+Shift+Enter: Run entire code chunk
Tab: Auto-complete function names and file paths
Ctrl+Z: Undo last action
Ctrl+Shift+C: Comment/uncomment selected lines
Ctrl+L: Clear console
Ctrl+1: Focus on script editor
Ctrl+2: Focus on console
Developing good habits early will save you time and frustration:
my-analysis/
├── data/ # Raw data files
├── R/ # R scripts
├── figures/ # Generated plots
├── out/ # Output files
└── README.md # Project descriptionUse descriptive names: student_grades not sg
Be consistent: if you use underscores, always use underscores
Avoid spaces in names: sales_data not sales data
Save your scripts frequently (Ctrl+S)
Use meaningful file names with dates
Consider version control (Git) for important projects
Always save important visualizations
Use consistent naming for plot files
Store plots in a dedicated folder
Common problems when loading data:
Use forward slashes: "data/myfile.csv" not "data\myfile.csv"
Check working directory: Use getwd() to see current location
Use relative paths: Avoid "C:/Users/YourName/Desktop/file.csv"
Check file extension: Ensure .csv files are actually CSV format
Encoding problems: Try fread(file = "file.csv", encoding = "UTF-8")
Delimiter issues: Some “CSV” files use semicolons or tabs
When you’re stuck, try these resources in order:
Built-in Help: Start with ?function_name
RStudio Cheatsheets: Help → Cheatsheets
Google Search: “R how to [your specific question]”
Stack Overflow: Include “R” in your search terms
RStudio Community: community.rstudio.com
Local User Groups: Search for “R User Group [your city]”
Congratulations! You’ve completed your introduction to R, RStudio, and Quarto. You now have a solid foundation for data analysis and report creation using modern, efficient tools.
Through this guide, you’ve learned to:
✅ Install and set up the complete R data science toolkit
✅ Perform basic mathematics and statistical calculations with fastverse
✅ Create and manipulate data using data.table()
✅ Generate professional visualizations with ggplot2
✅ Build comprehensive reports with Quarto
✅ Organize projects effectively in RStudio
✅ Troubleshoot common problems independently
✅ Apply best practices for reproducible research
✅ Use explicit arguments for clearer, more readable code
Now that you have the basics, here’s how to continue your learning journey:
Create a personal project: Analyze data you care about (sports, weather, personal finances)
Reproduce this tutorial: Try creating similar analyses with different data
Experiment with styling: Modify colors, themes, and formatting in your charts
Practice explicit arguments: Always use argument names in your functions
Learn more ggplot2: Explore different chart types (scatter plots, histograms, box plots)
Master data import: Practice reading different file formats and cleaning messy data
Develop your workflow: Create templates for common analyses
Explore fastverse: Learn more efficient functions for data manipulation
Statistical methods: Learn about hypothesis testing, regression, and correlation analysis
Advanced Quarto: Explore presentations, websites, and interactive documents
Package ecosystem: Discover specialized packages for your field of interest
Automation: Learn to create functions and automate repetitive tasks
R for Data Science (Wickham and Grolemund 2016): The definitive beginner’s guide
Quarto Documentation: Comprehensive guide to all Quarto features
ggplot2 Book: Deep dive into data visualization
fastverse Documentation: Learn efficient data manipulation
RStudio Education: Free courses and tutorials
Swirl: Learn R interactively within R itself
DataCamp: Structured courses (some free content)
R-bloggers: Daily articles and tutorials
#RStats Twitter: Active community sharing tips and resources
Local R Meetups: Network with other R users in your area
Remember that everyone starts as a beginner, and the R community is known for being welcoming and helpful. Don’t be discouraged if concepts take time to sink in—data analysis is a skill that develops with practice.
The tools you’ve learned today are used by:
Data scientists at major technology companies
Researchers at universities worldwide
Analysts in government and non-profit organizations
Students in fields from psychology to finance
Professionals in healthcare, marketing, and countless other fields
You’re now part of a global community of people using these powerful tools to understand the world through data.
Keep practicing, stay curious, and most importantly—have fun with your data analysis journey!
Remember: Always use explicit argument names, save your work regularly, and don’t hesitate to ask for help when you need it.
# Load all required packages for this tutorial
library(data.table) # Fast data manipulation and file reading
library(fastverse) # Collection of fast R packages for data science
library(tidyverse) # Collection of packages for data science workflow
library(readxl) # Read Excel files (.xlsx, .xls)
library(openxlsx) # Write Excel files and advanced Excel operations
library(knitr) # Dynamic report generation and table formatting
library(ggplot2) # Advanced data visualization (part of tidyverse)data.table (Dowle and Srinivasan 2023): A high-performance package for working with large datasets. It’s much faster than base R data.frame for reading, writing, and manipulating data.
fastverse: A collection of complementary packages that work together for fast and efficient data science. Includes functions like fmean(), fmax(), etc.
tidyverse (Wickham and Grolemund 2016): A collection of packages designed for data science, including ggplot2 for visualization, dplyr for data manipulation, and readr for data import.
readxl: Specifically designed to read Excel files. It can handle both .xlsx and .xls formats without requiring Excel to be installed.
openxlsx: Allows you to create and write Excel files with formatting, formulas, and multiple sheets.
knitr: Essential for creating dynamic documents. It processes R code chunks and creates formatted tables and reports.
ggplot2: Part of tidyverse, this is the most popular package for creating beautiful, publication-ready visualizations in R.
Happy analyzing!